

メタデータとは?
IBM iのDB2は、ファイル、フィールド、レコード件数、索引キー・フィールド、制約、読み込み、書き込みなどに関する情報を大量に保持しています。これらは一般的にメタデータと呼ばれています。
メタデータはDB2の性能を向上させるためのクエリオプティマイザーで使用され、多くは昔ながらのDSPFD、DSPFFD、i ナビゲーター、DB2の定義やプロパティという典型的なコマンドによって目にすることができます。
DDSよりもむしろSQL DLLで作成されたオブジェクトについては、SQLと関連するデータベースの強化によって、より多くの情報を確認することができるでしょう。
DB2 Web Queryでは、データベースとレポートインターフェースの間に作られたメタデータ・レイヤーを使用します。
テーブルやビュー、プロシージャーはWeb Queryに記述されているため、そのメタデータはファイルとして作成・保存されます。
その作成プロセスでは列の具体的情報とともに、データベース・オブジェクトの位置についてのデータもファイルに保存します。
この2つのメタデータファイルはシノニムと呼ばれていますが、実際には2つの異なったファイルが作られています。
メタデータ・レイヤーは、DB2 Web Queryがデータと表示情報を得られる場所へのポインターを提供します。
DB2 Web Query のメタデータはフィールド・レベルで記述された情報を提供するため、レポートを容易にするだけでなく、自社のビジネスがいまどのような状態にあるかを明確にしてくれます。
Web Queryがデータベースと通信するとき、そのメタデータはSQLを検索のために構築するやり方と、それらが返ってきたときの表示方式をシステムに伝えます。
Web Queryは適切なアダプターがあれば、DB2以外のデータべースでも使用可能です。
また、アダプターはオラクルJD Edwards製品のWorldやEnterprise Oneといった特定のERPシステムを処理するためにも利用できます。
これらは特殊な日付の書式や参照テーブルを利用しているケースもありますが、メタデータはWeb Queryにそのデータベース向けに詳細情報を処理させることができます。
例えばSQL serverのインスタンスについて、Web Queryはそのシステムを確認してSQL構文を適切に形式化するという流れです。
DB2 Web Queryでのメタデータ実例
では、ORDERS (受注) と名付けられたDB2のテーブルを使って実例を検討してみましょう。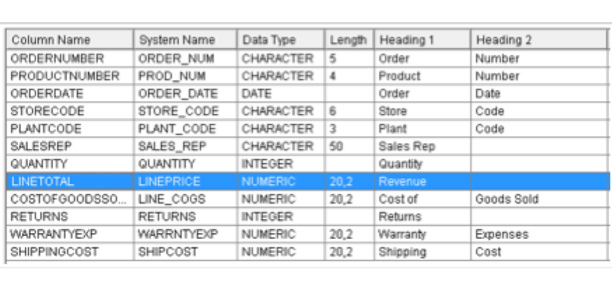
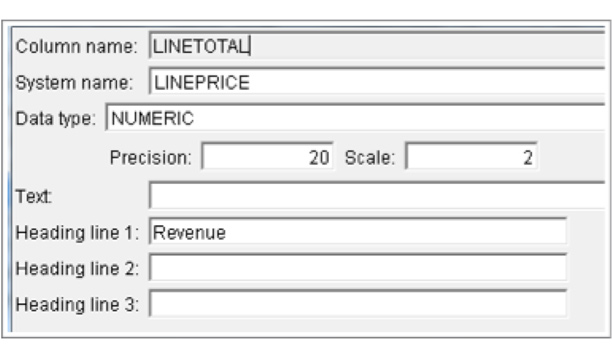
カラム名、システム名、データ・タイプ、テキストおよび見出しはすべてIBM i開発者には非常になじみ深い名称です。
各属性は、Web Queryメタデータの生成時に列の記述でその役割を果たしています。
このインスタンスでは、DDSフィールドかシステム名はLINEPRICE (価格) を表示し、エイリアスかSQL列名はLINETOTAL (合計額) を表示し、Heading-line-1はRevenueを読み込みます。
では、この列に言及するうえで好ましいものはこれら「タイトル」の内のどれでしょうか。
その答えは「場合による」なのですが、DB2 Web Queryはあなたにここで記述することのできる情報を特定したり、修正したり、あるいはそれ以上の作業を可能とします。
列のメタデータを作成したとき、DB2 Web Queryはまず、テーブル定義で見つけたものに基づいて仮定を立てます。
メタデータ・レイヤーが重要であるのは、それが列の見出し、説明文またはデータ形式に修正を加える機会を提供し、その構造全体での整合性を促進するからです。
場合によっては、オリジナルのERPデータベースを超えるレベルになります。
図の例では、Revenue列はこのORDERSテーブルからレポートを作成する分析者にとって完璧に明快なものかもしれません。
ところが、ERPデータベースの場合、列には時々XSINVNのように曖昧な名前や短縮された名前が付けられています。
ここでXSはExtended Sales (拡大した販売) を意味し、INVN はInvoice number (インボイス番号) を意味します。
他のテーブルでは、インボイス番号はAccounts receivable (売掛金勘定) と関連してARINVNと呼ばれるかもしれません。
これら2つの列についてのメタデータのタイトルはレポートでの明確性と整合性のため、「Sales Invoice No. (販売インボイス番号)」として標準化するほうがいいかもしれません。
メタデータの有用性
BIを使ったレポーティングの世界では、「Single Version of the Truth (一元性、一貫性の確保)」という言葉がよく出てきます。メタデータはそういった結果を得るために有効なものです。メタデータのメリットは列の命名に限りません。
フィールド型、サイズ、形式、表示、小数点の桁数、コンマ挿入または通貨記号を設定できます。
さらに、別に存在する数値フィールドから新たな列を計算して作成したり、フィールドの一部や日付フィールドの一部を抽出したい場合があるしれません。
また、DB2 Web Queryに組み込まれたさまざまな機能を利用してフィールド同士を連結させ、フィールドをある形式から別の形式へ変換することができます。
こうした機能は、基になったデータベースからデータが検索されたときに、それを記述・変換する力を提供します。
さらに重要なのは、メタデータを用意することによってレポート作成の時間を大幅に節約につながるということです。
例えば、もし売り上げドルが浮動通貨記号と3桁区切りのコンマという2つの特徴を持った13桁の10進数の値となるべきならば、これらすべてをメタデータ・フィールド定義内に設定できます。
すなわち、レポート作成する際に、これらの見た目とフィールドの状態をあらためて設定しなおす必要がないということです。
DB2 Web Query for iの可能性
IBMのDB2 Web Query for iは、他の多くの選択肢よりも低コストなBIソリューションを導入できるうえ、インストールも操作も簡単です。さらにはQuery/400またはRPGプログラムを置換するツールも提供されています。
DB2 Web QueryはBI ポータルをサポートし、その高い能力によって、さまざまな形式の膨大なレポーティングに対応します。
さらにモバイルアプリにより、レポートを各種デバイスで閲覧できます。
また、DB2 Web QueryはIBM iプラットフォーム以外でのデータウェアハウスとは大きく異なります。
なぜなら、DB2 Web Queryによって、ローカル・メタデータおよびローカルDB2データベースを一元管理できるからです。
レポートを作成するためにPower Systemsから別の機器やプラットフォームにデータをコピーしなければならないという面倒な状況は発生しません。
IBMはあなたのBIアプリケーションを別のIBM iインスタンス、別のシステムまたはLPARで実行することを可能にしています。
さらに、Web QueryをExpress EditionまたはStandard Editionで提供し、さらにデータウェアハウスの場でよく要求される抽出・変換・ロード (ETL) という工程を容易にするその他のBIも提供します。
メタデータ・レイヤーとその内容の詳細
以前の記事で、参照整合性制約で定義され、ひも付けされている関連テーブル4つを例として使用しました。次に同じ4つのテーブルでメタデータ・レイヤーとその内容について詳細を図解してみましょう。

メタデータと関連する2つのファイル型はAccessファイル (ACX) とMasterファイル (MAS) です (図4を参照)。
ACXはロケーションを記述し、MASは内容を記述します。
Web Queryはこれらのファイルを、Web Queryディレクトリー下部の1つ以上のフォルダー内にあるIntegrated File System (IFS) へ格納します(注意: /QIBM/UserData/qwebqry の下部を見てください)
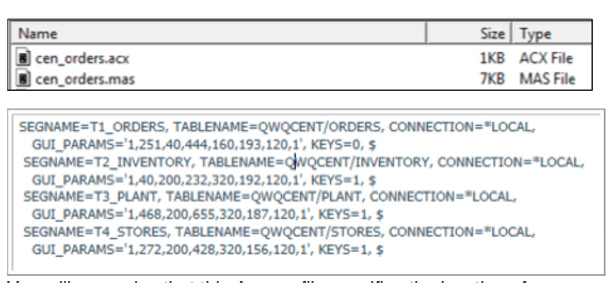

この例では、すべてのテーブルがたまたま同一のQWQCENTライブラリーに位置しています。
CONNECTION変数はローカルDB2 環境を指します。
メタデータの含むテーブルが1つであろうとそれ以上であろうと、各テーブルはテーブル名に対応するSEGMENTとして定義されます。
このセグメント情報はInfoAssistという設計ツールを通して実行されます。
このツールによってレポート内の各列のソースを見ることができます。
Masterファイルは各テーブルの詳細情報を含み、そのテーブル内のフィールドをリストします。
メタデータ内に1つ以上のテーブルが存在する場合、そのテーブルやセグメントは互いに共通するフィールドによって関連付けられます。
これは私たちがSQLでテーブルを結合するやり方と似ています 。
この例では、ORDERSテーブルが詳細な注文情報と他の3つのテーブル用のキーと対応するフィールドを含むことがわかります。
その他のテーブルもJOIN_WHEREステートメントが定義する関連付けによってORDERSにそれぞれが結合されています。
レポートの設計者は必ずしもリレーショナルデータベース内のJOININGデータの微妙な差異に気づかないかもしれないと考えれば、メタデータ内でテーブルを結合しておくこの機能には多大なるメリットがあります。
加えて、結合がひとたび定義されていれば、情報の豊富なDBAやシステムで定義された参照整合性制約によってそれがより正確になるというのは理にかなったことではないでしょうか?
その他いくつかの言及すべきメタデータの機能
・あなたが人に見られたくないフィールドを削除したり隠したりできます。・基となるデータベース内に存在してないフィールドを作成して追加できます。
これはORDERDATE_YEARフィールド (図-6の太字) でデモンストレーションされています。
このフィールドはORDERDATE (注文日) フィールドからYEAR (年) 部分をDPARTと呼ばれるビルトイン機能を使用して抽出しています。
このようなORDERDATE_YEARはDEFINEフィールドであり、メタデータ・レイヤー内にのみ存在し、SQLによってランタイムに数値フィールドとして生成されます。
・HIERARCHIES(階層)として知られるフィールド関連付けを定義できます。
これはオンライン分析処理 (OLAP) を容易にするもので、InfoAssistツール内にある任意でオンにできる別のタイプのドリルダウンです。
DB2 Web Queryでは、デフォルトのメタデータを作成することも、自身の好きな数だけオプションを利用して作成・編集を行うこともできます。
サイトによっては、そのテーブルとビューについての一時的なメタデータ作成の実行のみを選択してレポートの書き出しを開始するかもしれません。
別のサイトではメタデータの利用にもっと多くの時間を使い、形式、用語を標準化してOLAPのレポート作成を深く研究するかもしれません。
これがIBM DB2 Web Query for iのためのメタデータの外観です。
メタデータをチェックし、レポーティングでDB2 Web Query for iの性能をどれだけ有効に活用できるかを考えてみましょう。
====================
本記事は「IBM Systems Magazine」の許諾のもと、原文を日本語化するとともに、一部再編集したものです。
原文をご覧になりたい方は下記よりアクセスしてください。
原文タイトル: What is Metadata And Why Do I Need It?
原文著者: Rick Flagler








